Annotation Lexicale : Influence des Voisins Lexicaux
Responsable : Sandrine Ollinger
Membres : Alessia Della Rocca, Professeure contractuelle, Université de Vérone, Italie, Paolo Frassi, Professeur ordinaire, Université de Vérone, Italie, Évelyne Jacquey, CR, CNRS, ATILF, France, Sandrine Ollinger, IR CNRS, ATILF, France, Federica Patron, doctorante, Université de Vérone, Italie.
Le projet ALIVoLex se déroule du mois de novembre 2025 au mois de décembre 2026. Il est porté par le GR PAL et bénéficie d’un Trajectoire du pôle scientifique CLCS de l’Université de Lorraine.
Présentation générale
Le projet ALIVoLex fait suite au séminaire Digital Spritz du 25 juin 2025 de l’Université de Vérone.
Soit l’inventaire de sens de GRAND-MÈRE, composé de deux sens :
- GRAND-MÈRE I Mère de la mère ou du père d’une personne [Sa grand-mère lui a transmis sa sagesse.]
- GRAND-MÈRE II Femme considérée comme âgées. [La grand-mère du coin de la rue est charmante.]
Soit deux contextes dans lesquelles on trouve une occurrence du lemme grand-mère :
a) Les babas, les vieilles, les grand-mères ont envie que ça change !
b) C’est une petite grand-mère et la plus vieille de ses petits-enfants s’occupe d’elle.
Nous nous intéressons à la tâche d’annotation en sens lexicaux, qui consiste à associer l’un des sens de l’inventaire à chacune des occurrences présentes dans les contextes a) et b).
Plus précisément, nous souhaitons évaluer l’influence de la présence, dans les contextes, de voisins lexicaux sur la difficulté de la tâche.
La notion de voisins lexicaux renvoie ici à la théorie des graphes. Le Réseau Lexical du français (RL-fr), comme tous les systèmes lexicaux, est un graphe petit monde. Chaque sens de notre inventaire correspond à un noeud de ce graphe. On désigne comme voisins lexicaux d’un sens donné, l’ensemble des unités lexicales reliées à celui-ci dans le graphe par au moins une relation lexicale paradigmatique ou syntagmatique. La figure Fig. 1 illustre les voisins lexicaux de GRAND-MÈRE I et GRAND-MÈRE II dans le RL-fr.
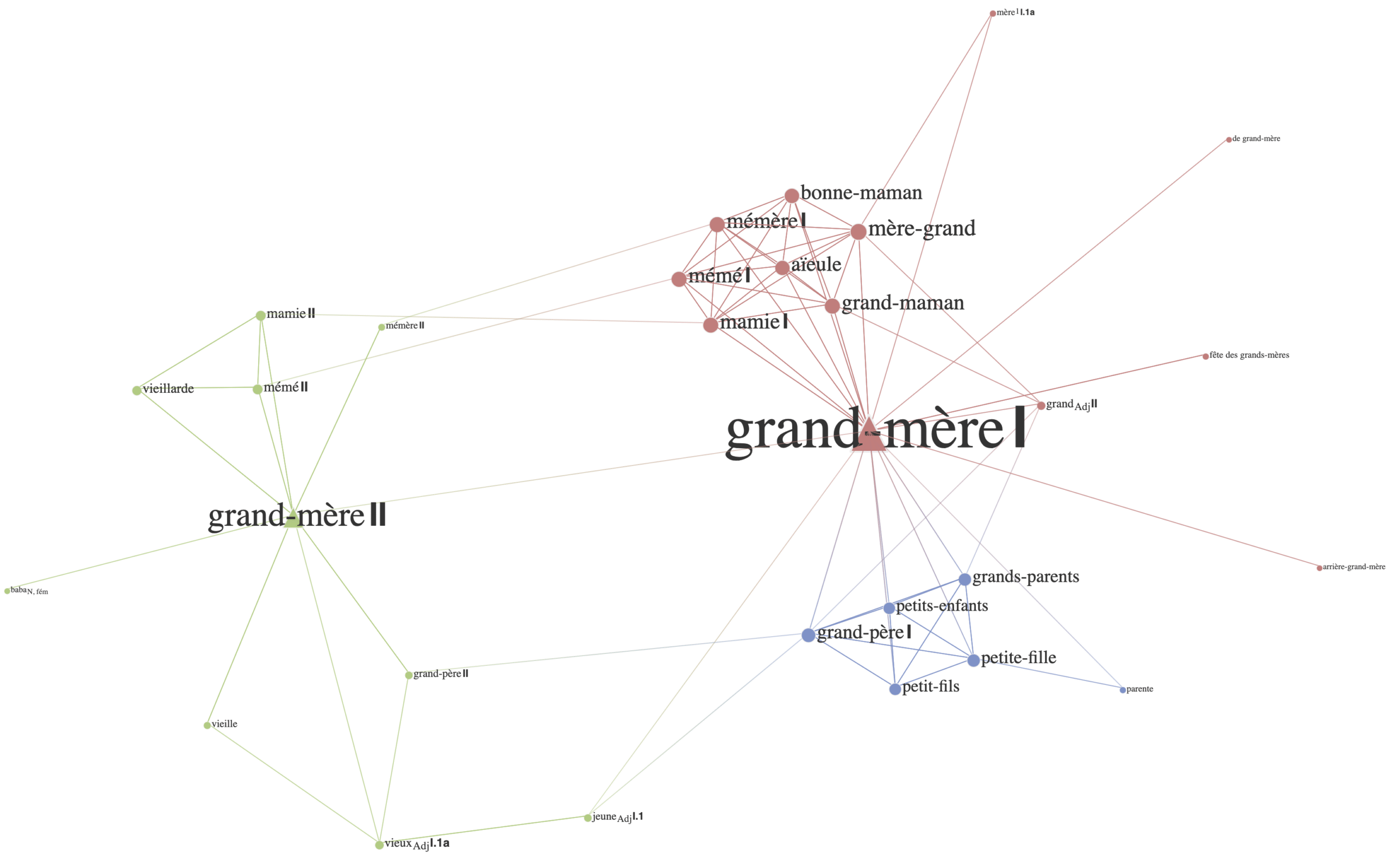
Fig. 1 Sous-graphe des voisins de GRAND-MÈRE I et GRAND-MÈRE II dans le RL-fr
Dans le contexte a), on observe une occurrence de BABA, voisin lexical de GRAND-MÈRE II et une occurrence de VIEILLE, voisin lexical de GRAND-MÈRE II :
a) Les babas, les vieilles, les grand-mères ont envie que ça change !
Dans le contexte b), on observe une occurrence de VIEUX Adj, voisin lexical de GRAND-MÈRE II et une occurrence de PETITS-ENFANTS, voisin lexical de GRAND-MÈRE I :
b) C’est une petite grand-mère et la plus vieille de ses petits-enfants s’occupe d’elle.
Nous faisons l’hypothèse que le contexte a) sera plus facile à annoter que le contexte b), en raison de la consistance des informations véhiculées par les voisins lexicaux présents dans le contexte, qui sont tous associés au sens GRAND-MÈRE II.
De plus, nous souhaitons évaluer si la tâche est facilitée par le fait d’attirer l’attention des répondants sur les occurrences de voisins lexicaux à l’intérieur des contextes.
Méthodologie
Choix de deux lemmes polysémiques (1 nom et 1 verbe) en lien avec le programme du cours de linguistique française de Paolo Frassi.
Constitution d’un corpus de 20 contextes par lemme, annotés en voisins lexicaux, sélectionnés pour respecter les contraintes suivantes : 10 contextes dont les voisins désignent 1 seul sens, 10 contextes dont les voisins désignent plus d’un sens ; tous de longueur comparable ; de complexité syntaxique comparable.
Quatre questionnaires seront élaborés à partir de ce jeu de données : A.1 20 contextes du lemme nominal sans annotation A.2 20 contextes du lemme verbal sans annotation B.1 20 contextes du lemme nominal annotés en voisins lexicaux (à l’aide des outils développés dans le cadre du projet ALUMCoCo) B.2 20 contextes du lemme verbal annotés en voisins lexicaux.
Lors d’une séance du cours de linguistique française de Paolo Frassi, les étudiants seront séparés en deux groupes. Le premier groupe répondra au questionnaire A.1 puis au questionnaire B.2 ; le second groupe répondra au questionnaire A.2 puis au questionnaire B.1.
Pour chaque contexte proposé, les étudiants devront choisir le sens présent parmi les sens de l’inventaire proposé.
Les étudiants inscrits à ce cours sont au nombre de 70. Il s’agit d’étudiants en 2e année, qui ont un niveau de français qui se situe entre B1 et B2.
Différents indicateurs seront enregistrés lors de cette collecte de données, qui feront l’objet d’une analyse qualitative et quantitative.
Références
Martínez Alonso H, Johannsen A, Lopez de Lacalle O, et al. (2015) Predicting word sense annotation agreement. In: Proceedings of the First Workshop on Linking Computational Models of Lexical, Sentential and Discourse-level Semantics (eds M Roth, A Louis, B Webber, et al.), Lisbon, Portugal, September 2015, pp. 89–94. Association for Computational Linguistics.
Barque L, Huyghe R and Foegel M (2025) Exploring lexical factors in semantic annotation: insights from the classification of nouns in French. Language Resources and Evaluation. Springer Verlag. Epub ahead of print January 2025.
Loiseau S, Gréa P and Magué J-P (2011) Dictionnaires, théorie des graphes et structures lexicales. Revue de Sémantique et Pragmatique (27): 51.
Polguère A (2009) Lexical Systems: Graph Models of Natural Language Lexicons. Language Resources and Evaluation 43(1). Springer: 41–55.
Watts DJ and Strogatz SH (1998) Collective dynamics of /`small-world/’ networks. Nature 393(6684): 440–442.
| Étapes | |||
| 14 avril 2026 | Paolo Frassi | enquête auprès des étudiants | |
| 23 mars 2026 | Alessia Della Rocca Paolo Frassi Évelyne Jacquey Sandrine Ollinger | réunion en ligne | - fin de la sélection des contextes - questionnaire Limesurvey - enquête et utilisation didactique des ressources lexicales |
| 9 mars 2026 | Alessia Della Rocca Paolo Frassi Évelyne Jacquey Sandrine Ollinger Federica Patron | réunion en ligne | - sélection de contextes pour l'enquête |
| 2 mars 2026 | Alessia Della Rocca Paolo Frassi Évelyne Jacquey Sandrine Ollinger Federica Patron | réunion en ligne | - retour annotation INCePTION |
| 23 février 2026 | Alessia Della Rocca Paolo Frassi Sandrine Ollinger Federica Patron | réunion en ligne | - organisation colloque 2027 |
| 16 février — 2 mars 2026 | Alessia Della Rocca Paolo Frassi Évelyne Jacquey Sandrine Ollinger Federica Patron | annotation des contextes pré-sélectionnés dans INCePTION | |
| 16 février 2026 | Alessia Della Rocca Paolo Frassi Évelyne Jacquey Sandrine Ollinger Federica Patron | réunion en ligne | - définitions simples et illustrations de sens |
| 9 février 2026 | Alessia Della Rocca Paolo Frassi Évelyne Jacquey Federica Patron | initiation à INCePTION en ligne | |
| 28 janvier — 16 février 2026 | Paolo Frassi Évelyne Jacquey Sandrine Ollinger | préparation des données | |
| 28 janvier 2025 | Paolo Frassi Évelyne Jacquey Veronika Lux Pogodalla Sandrine Ollinger Alain Polguère | réunion en ligne | - méthodologie de pré-sélection de contextes - structures polysémiques de GOÛT et TRAVERSER |
| 10 décembre 2025 | Paolo Frassi Évelyne Jacquey Sandrine Ollinger | réunion en ligne | |
| 5 novembre 2025 | Paolo Frassi Évelyne Jacquey Sandrine Ollinger | réunion en ligne | |
| Publications |
| Communications |